

Explorando la diversidad del español, porque el español no es solo uno
Lectura rápida
- El estudio contribuye al objetivo más amplio de una representación lingüística justa en las tareas de generación y comprensión de texto impulsadas por inteligencia artificial.
- Es fundamental que todas las formas de hablar estén representadas en los modelos de lenguaje. No es solo una manera de hablar español; es también su cultura.
- La migración influye directamente en los dialectos del español porque provoca contacto entre hablantes de distintas variedades.
- Así como existe preocupación por los idiomas minoritarios (euskera, gallego, quechua, etc.), también debería existir por los dialectos del español, que son hablados por millones de personas. Ellos también merecen que su cultura sea representada.
- SomosNLP: misión es acercar la IA a 600 millones de personas hispanohablantes alrededor del mundo y conseguir una justa representación del español y lenguas cooficiales en el mundo digital.
El español está presente en todos los continentes y es el segundo idioma más hablado del mundo. El país del que proceden los autores del nuevo estudio cuenta con una rica diversidad lingüística, donde, además del español estándar, existen también lenguas regionales con sus propias reglas y vocabulario.
Nos referimos, por supuesto, a España.
España, el país de Miguel de Cervantes, Federico García Lorca, Santiago Ramón y Cajal…También es sede de una de las bibliotecas más grandes del mundo, la Biblioteca Nacional de España, fundada hace más de 300 años, y de la Real Academia Española , la institución más importante para el estudio del español. Fue fundada en 1713 con el fin de normalizar y promover el español, asegurando su correcta y uniforme utilización… Y la lista continúa.
En esta riqueza reside un reto moderno: preservar el español en la era de la inteligencia artificial. Cientos de millones de personas hablan español y su diversidad lingüística refleja la riqueza de culturas y dialectos. Comprender estas diferencias es crucial para preservar la diversidad lingüística y una representación justa en los sistemas de IA. Reconocer el español en todas sus formas no significa luchar contra molinos de viento; si has leído El Quijote, sabes a qué nos referimos.
Un equipo de investigadores españoles abordó este tema en un nuevo estudio, “El español no es solo uno: un conjunto de datos para el reconocimiento de dialectos españoles en LLMs”. Gonzalo Martínez, Marina Mayor-Rocher, Cris Pozo Huertas, Nina Melero, María Grandury y Pedro Reviriego señalan que este trabajo contribuye al objetivo más amplio de una representación lingüística justa en las tareas de generación y comprensión de texto impulsadas por inteligencia artificial.
Sobre este estudio, hablamos con Gonzalo Martínez Ruiz de Arcaute, quien es también autor del estudio publicado en 2023 y que se centró en la interacción de los modelos generativos de IA con Internet, y con Marina Mayor-Rocher.
Resumen del trabajo realizado por los autores: “levantarse” o “pararse”
En el mundo de la inteligencia artificial, los grandes modelos de lenguaje (LLM, por sus siglas en inglés), como ChatGPT, se han convertido en herramientas clave para generar y comprender el lenguaje. El español incluye numerosas variedades con vocabulario, gramática y matices culturales diferentes. A pesar de esta diversidad, las pruebas y evaluaciones estándar de inteligencia artificial a menudo pasan por alto estas diferencias, lo que puede llevar a resultados sesgados o incompletos.
Para llenar este vacío, los investigadores han desarrollado un conjunto de datos especializado de 30 preguntas de opción múltiple, diseñado para evaluar la capacidad de los LLM para reconocer y utilizar los diferentes dialectos del español. Las preguntas fueron cuidadosamente elaboradas por expertos en lingüística y variaciones del idioma español, con el objetivo de garantizar precisión, claridad y adecuación cultural. Cada pregunta aborda aspectos lingüísticos clave, como el orden de los elementos sintácticos en la oración, la elección de palabras y el uso de formas verbales que reflejan diferencias regionales.
Por ejemplo, mientras que en México y gran parte de Centroamérica se utiliza la expresión “levantarse” para “ponerse de pie”, en Argentina se usa “pararse”. Estas diferencias son cruciales para evaluar la capacidad del modelo de distinguir dialectos. La aplicación de este conjunto de datos tiene múltiples beneficios.
Primero, permite a investigadores y desarrolladores identificar sesgos de los LLM hacia ciertos dialectos y corregirlos. Esto significa que los modelos no solo favorecen el “español genérico”, sino que también pueden interpretar y usar con precisión las distintas variantes del idioma. Segundo, el conjunto de datos es útil con fines educativos. Los estudiantes de español pueden usarlo para familiarizarse con las diferencias regionales, mientras que los hablantes nativos pueden evaluar cuánto entiende la inteligencia artificial su dialecto. Tercero, los sociolingüistas pueden aplicar el conjunto de datos para estudiar factores sociales en el uso de dialectos, como el nivel educativo o la clase social.
Un experto en lingüística elaboró el conjunto inicial de preguntas que reflejan diferencias dialectales. Luego, dos lingüistas adicionales revisaron las preguntas para garantizar claridad, precisión y adecuación cultural. Finalmente, las preguntas se probaron en varios LLM para verificar la comprensión de las tareas y la efectividad en el reconocimiento de dialectos. Al reconocer los dialectos y evaluarlos adecuadamente, los modelos pueden ser más precisos, justos y útiles para todos los hablantes de español.
Consideramos fundamental que todas estas formas de hablar estén representadas en los modelos de lenguaje
¿Cómo se les ocurrió la idea de este estudio?
Gonzalo Martínez Ruiz de Arcaute: Dentro del mundo del procesamiento del lenguaje existe una gran conciencia sobre la importancia de que los LLMs sepan idiomas minoritarios. En España, por ejemplo, contamos con lenguas cooficiales como el gallego, el catalán o el euskera (y en el mundo existen muchas más) y muchos de los trabajos van en esa dirección. Sin embargo, no ocurre lo mismo con las distintas variedades del español en América, que, teniendo muchos más hablantes, no reciben la misma atención. Incluso dentro de España, las diferencias son grandes: una persona del norte, como es mi caso en el País Vasco, no se expresa igual que alguien de Andalucía (existe una película muy conocida, “8 apellidos vascos”, sobre estas diferencias). Y si miramos a Latinoamérica, donde se encuentra la mayoría de los hablantes de español, esas variaciones son todavía más amplias…
Por eso consideramos fundamental que todas estas formas de hablar estén representadas en los modelos de lenguaje. No es solo una manera de hablar español; es también su cultura. En la misma línea está el proyecto CEREAL, donde analizaron los datasets públicos utilizados por estas empresas para entrenar modelos. Descubrieron que la gran mayoría de los datos corresponden al español peninsular y que las variedades hispanoamericanas apenas están representadas. Esta falta de equilibrio constituye un problema para que todas las culturas hispanohablantes estén representadas. Esto puede ser un problema mayor en el futuro.
Estos modelos se entrenan con grandes volúmenes de datos extraídos de internet, pero hoy en día buena parte de ese contenido ya está generado por las propias herramientas de IA. Esto implica que el material artificial podría alimentar a la siguiente generación de modelos, con el riesgo de reforzar sesgos. Si, por ejemplo, el sistema solo produce textos en una variedad concreta del español, eso podría terminar influyendo en la manera en que se comunica toda la comunidad hispanohablante.
¿Hay suficientes estudios como este y qué les gustaría cambiar en la forma en que se reportan estos estudios?
Gonzalo Martínez Ruiz de Arcaute: Creemos que no hay suficientes. El mundo del procesamiento del lenguaje está muy centrado en torno al inglés, y en inglés no existen tantas diferencias entre variedades (Reino Unido, Estados Unidos, Australia) como en el español. Sí, hemos visto algún artículo sobre variedades del hindi y del chino, aunque no conocemos en detalle esos casos. Pero lo que más nos gustaría es que la comunidad tomara más conciencia para evitar los problemas que comentábamos antes.
La migración influye directamente en los dialectos del español porque provoca contacto entre hablantes de distintas variedades
¿Cómo afecta la migración a los dialectos del español?
Marina Mayor Rocher: La migración influye directamente en los dialectos del español porque provoca contacto entre hablantes de distintas variedades. Según la teoría de la acomodación lingüística, las personas ajustan su forma de hablar (léxico, pronunciación, gramática) para acercarse o distanciarse del grupo en el que se insertan. El cambio puede ir en dos direcciones: convergencia o divergencia. Los migrantes convergen cuando tienden a adaptar su habla al dialecto dominante del nuevo entorno para facilitar la comunicación y buscar aceptación social.
Por ejemplo, yo estudié la integración sociolingüística de los migrantes paraguayos en Madrid y estos declaraban haber adoptado algunas expresiones léxicas peninsulares para mejorar el entendimiento de los españoles (vale, en vez de dale, o falda en vez de pollera). La divergencia, por el contrario, ocurre cuando los migrantes mantienen o refuerzan su dialecto original como forma de preservar su identidad cultural o de marcar diferencia frente al grupo receptor. En el mismo estudio, descubrimos que algunos paraguayos recurrían a la lengua guaraní para comunicarse con sus compatriotas y evitar que otros hispanohablantes pudieran entenderlos.
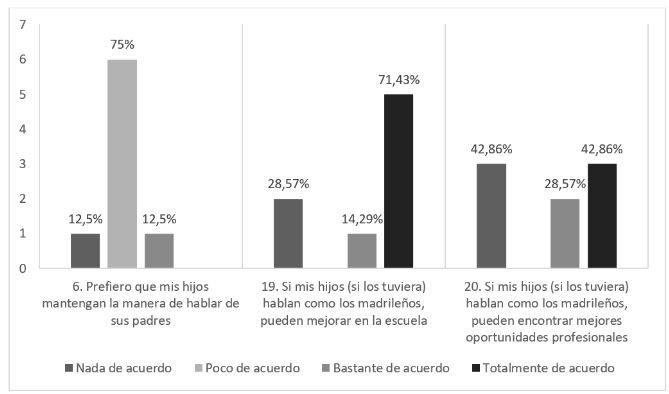
Justo en el trabajo publicado en junio del año pasado, Marina Mayor-Rocher estudió la integración sociolingüística de los paraguayos en Madrid y la vitalidad del guaraní. La convergencia hacia el español madrileño es parcial y se limita principalmente al léxico y a los cambios pronominales, independientemente del tiempo de residencia o del género. La identidad de los paraguayos está más vinculada al guaraní, que se utiliza en casa, con amigos y en la comunicación con otros compatriotas. Existe una disonancia entre las actitudes lingüísticas y el uso real del idioma: aunque mantienen su dialecto propio, los paraguayos valoran el español madrileño y desean que sus hijos lo aprendan por ventajas sociales y profesionales. La transmisión del guaraní a las generaciones más jóvenes es débil, pero los adultos siguen utilizándolo y las mujeres subrayan la importancia de preservar la tradición lingüística para sus hijos.
¿Puede la migración crear nuevos dialectos mixtos? ¿Significa esto que los LLM necesitan mejorar/adaptarse?
Marina Mayor Rocher: Por supuesto, la migración puede dar origen a nuevos dialectos mixtos o, mejor planteado, a la evolución hacia un nuevo dialecto como consecuencia del contacto de lenguas. Cuando hablantes de diferentes regiones conviven, se produce una acomodación mutua sostenida, que termina consolidando nuevas formas lingüísticas estables (por ejemplo, el “espanglish” en contextos bilingües). Desde la perspectiva de la acomodación lingüística, este proceso implica una adaptación bidireccional y dinámica del habla. Por lo tanto, los LLM también deberían adaptarse continuamente para reflejar esa variación y evolución real del idioma y para ello necesitan entrenarse con datos dialectales diversos y ajustarse en su salida al interlocutor, contexto y registro comunicativo.
El impacto de la velocidad del habla: el español se considera uno de los idiomas más rápidos, con un promedio de 7,82 sílabas por segundo
¿Cómo puede afectar la velocidad del habla? ¿Qué tan importante es tener esto en cuenta?
Marina Mayor Rocher: No soy experta en procesamiento del habla, pero entiendo que los LLM es esencial comprender y ajustar la prosodia y el ritmo del habla para generar interacciones naturales y adaptadas a distintas comunidades dialectales. La prosodia es una de las características más distintivas entre dialectos. Por ejemplo, una persona del centro septentrional (Madrid) puede identificar que una persona es del norte de España solo por sus contornos prosódicos.
La representación de dialectos es importante y se necesita más trabajo en esta dirección
Este es un estudio muy útil, por ejemplo, para aplicaciones de voz. ¿Dónde creen que se puede aplicar más?
Gonzalo Martínez Ruiz de Arcaute: Justo es una línea que queremos explorar en el futuro. El texto es solo una de las formas de comunicación con los modelos, pero creemos no será la principal. Queremos analizar también modelos auditivos y de generación de voz: ¿pueden entender y simular todos los acentos? ¿Cuáles sí? ¿Cuáles no? Existen colegas trabajando en la misma dirección y, si te interesa, puedo recomendarte sus trabajos.
En cuanto a las aplicaciones, creemos que son útiles en todos los modelos generativos. Es fundamental que sean diversos y justos para todos. No puede ser que un modelo tenga un sesgo tan marcado hacia una región concreta, porque eso puede perjudicar y sesgar la cultura de muchos pueblos hispanohablantes.
¿Cuál es el impacto a largo plazo de estudios como este en las tecnologías de traducción y comunicación?
Gonzalo Martínez Ruiz de Arcaute: Sabemos que nuestro impacto es ínfimo comparado con grandes empresas como OpenAI, Anthropic o Google, que son quienes desarrollan estos modelos y pueden solucionar estos problemas. Lo único que buscamos es convencer a la comunidad científica de que la representación de dialectos es importante y que se necesita más trabajo en esta dirección. Así como existe preocupación por los idiomas minoritarios (euskera, gallego, quechua, etc.), también debería existir por los dialectos del español, que son hablados por millones de personas. Ellos también merecen que su cultura sea representada.
Este tema combina cultura, tecnología y lenguaje, así que me gustaría preguntarles si notan el impacto de la tecnología en el lenguaje.
Gonzalo Martínez Ruiz de Arcaute: Es algo que nos encantaría explorar: cómo han podido impactar estas tecnologías en el idioma español. Sí que existen artículos en inglés sobre cómo muchas palabras han cambiado y se utilizan más que otras, como “delve”, que curiosamente ChatGPT utilizaba en exceso antes. Esa historia es muy curiosa; parece que estas compañías contrataban mano de obra en países africanos de habla inglesa y en esos países esa palabra era muy común.
SomosNLP: Acercar la IA a 600 millones de personas hispanohablantes alrededor del mundo
Al ser preguntado sobre sus planes a futuro, Martínez Ruiz de Arcaute respondió: “Seguimos trabajando muy cerca con la asociación SomosNLP, que busca democratizar el español en el procesamiento del lenguaje. Desde hace años organizan hackatones, un leaderboard de mejores modelos en español y otras iniciativas increíbles para la comunidad hispanohablante.”
La comunidad SomosNLP fue fundada en marzo de 2021 por María Grandury, investigadora de la Universidad Politécnica de Madrid, con el objetivo de crear una plataforma inclusiva para todos los hispanohablantes del mundo. Desde sus inicios, SomosNLP ha reunido a expertos en IA, investigadores y entusiastas apasionados por el español, con la misión de impulsar las herramientas de IA para el español y garantizar una representación justa de todos los dialectos y variantes lingüísticas. Todas las personas, independientemente de sus conocimientos previos, son bienvenidas a unirse a la comunidad, participar en proyectos y en el desarrollo de recursos, compartir información, organizar eventos y crear contenido que contribuya a la visibilidad y al crecimiento del español en el mundo digital.
Para aclarar, PLN es la abreviatura de “procesamiento del lenguaje natural” (en inglés, NLP: Natural Language Processing). Es la rama de la inteligencia artificial (IA) que se ocupa de que las computadoras comprendan, interpreten y generen el lenguaje humano.

“Queremos seguir colaborando con ellos para mejorar los recursos de PLN en español, que todavía están demasiado sesgados hacia el inglés. Lo que más nos ha gustado de este trabajo es su rápida aceptación que cada vez existan más personas concienciadas por estos temas. Somos una comunidad internacional de personas hispanohablantes apasionadas por el PLN. Nuestra misión es acercar la IA a 600 millones de personas hispanohablantes alrededor del mundo. Y nuestra visión, conseguir una justa representación del español y lenguas cooficiales en el mundo digital,” concluye Martínez Ruiz de Arcaute.
La investigación de Gonzalo Martínez, Marina Mayor-Rocher y sus colegas no solo identifica las diferencias, sino que también destaca la importancia de representar de forma justa estas variaciones en los LLM. En una era en la que los modelos de IA se basan en grandes cantidades de datos en línea, es fácil sobreestimar las variantes lingüísticas dominantes e ignorar las menos conocidas o regionales. En general, el trabajo de los investigadores nos recuerda la importancia de un enfoque interdisciplinario: la lingüística, la sociología, los estudios culturales y la tecnología deben colaborar para comprender la lengua como un sistema vivo. Todo esto sugiere que la diversidad del español no es un obstáculo, sino una oportunidad: para la educación, para mejores modelos lingüísticos y también para construir un espacio digital que incluya a todos los hablantes.
Image: El Español Lengua Global
Este trabajo fue apoyado por los proyectos FUN4DATE (PID2022–136684OB-C21/C22) y SMARTY (PCI2024–153434) financiados por la Agencia Estatal de Investigación (AEI) 10.13039/501100011033 de España, por el proyecto de la Unión Europea Chips Act Joint Undertaking SMARTY (Subvención n.º 101140087) y por el Programa de Acceso a Investigadores de OpenAI. La evaluación también se realizó en parte con equipos que fueron donados por NVIDIA para apoyar la investigación.